

UX · UI · AI PRODUCT
Scout
Scout is an AI-native hiring intelligence platform built under ForgeField. By analyzing a resume against a job description, Scout deploys nine specialized AI agents that independently evaluate candidate fit and synthesize their findings into a comprehensive assessment.
The platform transforms raw documents into actionable insights, highlighting strengths, identifying gaps, and generating recruiter-ready outreach recommendations.
- Year
- 2026 — Ongoing
- Discipline
- UX · UI · AI Product
- Role
- Co-founder · Designer
- Team
- Arnab Gupta · Angshuman Roy (Dev)

CONTEXT
A 0→1 product under a new studio
Building an AI-native product from scratch
Scout became the first product developed under ForgeField, a studio focused on creating AI-native applications. Rather than treating AI as a feature layered onto an existing workflow, we explored a different question:
What happens when AI becomes the product's core engine, and the interface exists primarily to make its reasoning understandable? Most resume tools rely on keyword matching and ATS optimization. We believed modern language models could provide a deeper understanding of candidate fit by evaluating context, experience, and evidence—not just terminology.
METHODOLOGY
From discovery to product validation
Job-seeker interviews, competitor scan (Teal · Jobscan · Rezi), state-of-the-art LLM survey.
Problem statement, scope guard-rails, success metrics, agent role taxonomy.
Single-LLM vs multi-agent architecture, agent personalities, score model.
Dashboard states, review form, analysis run flow, agent-detail modal, history.
Beta users running real applications, accuracy benchmarking, cost & latency tuning.
THE PROBLEM
Why resume tools still feel dumb
Shallow keyword matching
A senior engineer who wrote “led” instead of “managed” scores 60% against a JD that uses “managed”. The bar is vocabulary, not capability.
Black-box scores
Tools return a number. They rarely show why. The user can’t tell whether the score is about skills, experience, or formatting.
Single-pass analysis
One model evaluating skills, experience, narrative, and presentation in one prompt produces shallow conclusions on each. Specialisation is missing.
No actionable output
After reading the report, the user still has to translate insights into action. The bridge from analysis to outreach is left to them.
ARCHITECTURE
Why existing resume tools fall short
Single LLM, one prompt
Send resume + JD + scoring rubric to a single model and ask for a structured report. Simple, cheap, fast. But: one prompt has to do everything — skills, experience, narrative, presentation — and the output reads like a generalist gave it 30 seconds. Findings stay shallow, evidence stays vague, the user gets a number with no rationale.
Nine specialist agents in parallel
Each agent reads the same input through a single lens — skills, experience, compliance, education, narrative, readiness, portfolio, research, presentation. Each returns its own positive signals, gaps, risk flags, and evidence coverage. An orchestrator assembles the team's verdict. The user sees the team, not the model.
WHY IT MATTERS
A team of specialists is legible. A black-box model is not. The architecture decision is also the design decision.
INFORMATION ARCHITECTURE
Shape of the product
Dashboard
Upload + paste JD
Review
Verify extracted data
Loading
9 agents in parallel
Results
Score + breakdown
Agent Modal
Per-agent drill-in
History
Past analyses
THE NINE AGENTS
A team you can name.
Rather than presenting AI as a single black box, Scout introduces a team of specialists, each responsible for a distinct aspect of evaluation.
Marcus
Skill Analyst
Maps your skills to the role.
Lucas
Experience Evaluator
Reviews your work history.
Elena
Compliance Reviewer
Checks credentials & compliance.
Oliver
Education Assessor
Evaluates your academic background.
Sofia
Narrative Analyst
Analyses your career story.
Ethan
Readiness Evaluator
Assesses professional readiness.
Aria
Portfolio Reviewer
Examines your body of work.
Caleb
Research Analyst
Reviews publications & research.
Nova
Presentation Specialist
Evaluates how you present your work.
DESIGN SYSTEM
Clarity over decoration
Color palette
Teal #10A788
Brand · Primary CTAs · Logo
Ink #111827
Headings · Primary text
Slate #6B7280
Body text · Labels
Surface #F9FAFB
Page background · Cards
Success #10B981
Strong fit · Stored · Confirmations
Destructive #DC2626
Errors · File rejection
Type
Inter — for the entire product.
Inter Regular for body, Inter Medium for emphasis. No display font — the product is informational, not decorative. Restraint is the visual language.
Components
AppHeader · AppFooter · Button (primary / outline / disabled) · Badge (stored / active / strong) · Alert (destructive) · Dialog (overlay + content + header + footer) · ResumeListItem · Textarea · UploadDropZone · AgentCard. Every state designed, every variant catalogued.
KEY SCREENS
The product, end to end.
Upload + paste
Two-input entry surface with the Start Analysis button bridging both panels.

Verify extracted data
A 17-section accordion where the user corrects whatever the AI mis-parsed.

Nine agents working
The team becomes visible — each card pulses with a live micro-status.

The verdict
Score, top strengths, top gaps, agent breakdown, and a draft outreach message.

Drill into one lens
Positive signals, gaps, risk flags, evidence coverage, agent’s note.

A track record
Past analyses with stat cards and a sortable table.

AGENT DRILL-IN
Each agent's report, on demand.
Clicking any agent on the Results dashboard opens a focused modal — five named blocks, each addressing a different question a serious user would ask.
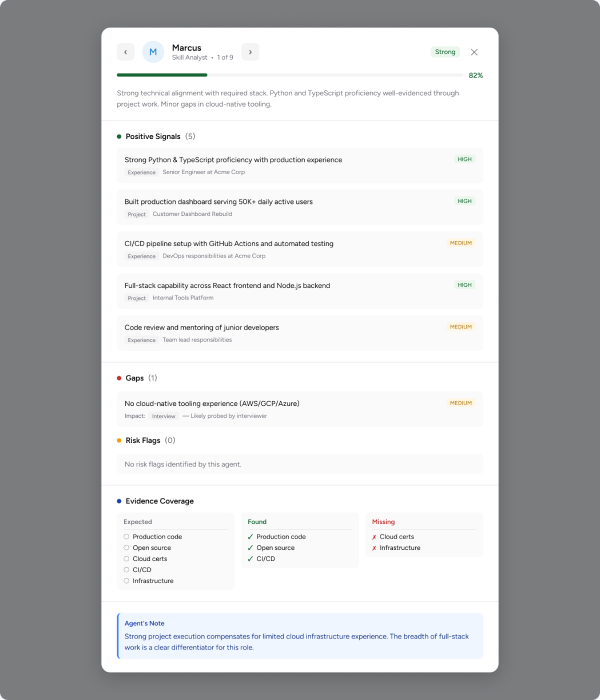
Positive Signals
What the agent saw that supports the candidate. Tagged HIGH / MEDIUM confidence with the evidence behind each finding.
Gaps
What’s missing for this role, with Impact tags (Interview, Resume, Project) showing where each gap will surface.
Risk Flags
Things the user should pre-empt — career gaps, vague experience, unverifiable claims. Often the most useful block.
Evidence Coverage
A 3-column Expected / Found / Missing list. Calibrates how much of the role’s expected evidence actually exists.
Agent’s Note
A 1-2 sentence narrative from the agent, in plain English. The part the user reads first.
REFLECTION
Key Takeaways
Designing an AI-native product taught me that the UI is the explanation. When the model does the work, the interface’s job shifts from collecting input to translating intelligence — making confidence visible, making evidence inspectable, making the model’s reasoning legible enough for a person to trust. Scout is the first product I’ve built where that distinction shaped every screen.
A FINAL WORD
The true value of Scout is not the final score,
It's the transparency behind that score.
Scout V2 is in progress — sharper agent reasoning, per-agent confidence calibration, mobile, and a recruiter outreach surface. ForgeField's second product is in scoping.